Grâce aux Field Models entraînables, Transkribus vous permet de reconnaître et de transcrire automatiquement de nombreuses mises en page. Voici les étapes à suivre pour entraîner un Field Model performant.
Comment entraîner un Field Model
1. Préparer les données d'entraînement dans le Transkribus Desk
Afin d'entraîner un Field Model, vous devez d'abord préparer les pages et les données sur lesquelles le modèle sera entraîné, également appelées données d'entraînement. Pour préparer ces données, importez les documents historiques que vous souhaitez utiliser pour l'entraînement dans une collection spécifique dans l'espace de travail (Transkribus Desk). Ensuite, ouvrez-les dans l'éditeur Transkribus pour dessiner des régions de texte et ajouter des lignes. Puis, balisez la structure, c'est-à-dire les éléments de mise en page de vos documents, comme expliqué dans cet article, et enregistrez les modifications.
Une fois que vous avez balisé un nombre suffisant de pages (nous recommandons au minimum 50 pages, selon la complexité de la mise en page de votre document), il est temps de commencer l'entraînement du modèle.
 2. Entraîner un modèle avec Transkribus
2. Entraîner un modèle avec Transkribus
La configuration de l'entraînement se compose de cinq étapes : Données d'entraînement, Sélection des balises, Données de validations, Configuration du modèle et Aperçu & lancement. Vous pouvez passer à l'étape suivante ou à l'étape précédente quand vous le souhaitez en cliquant sur les boutons « Next » et « Back ».
Veuillez noter que les données d'entraînement et les données de validation sont deux parties différentes du même jeu de données. Les données d'entraînement sont un ensemble d'exemples utilisé pour adapter les paramètres du modèle (le modèle est entraîné sur ces pages). En revanche, les données de validation servent de données de test indépendantes permettant une évaluation impartiale de la précision d'un modèle.
Étape 1 : Sélectionner les données d'entraînement
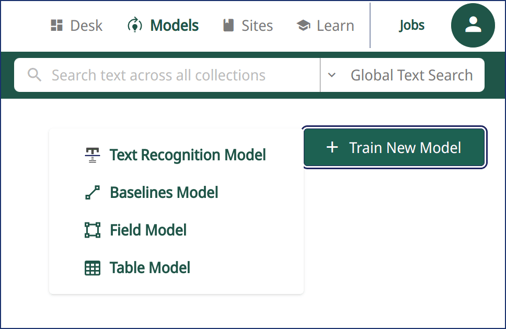
Accédez à l'espace de travail Transkribus Models , cliquez sur « Train New Model » et sélectionnez « Field Model » pour ouvrir le menu d'entraînement des Field Models.
Désignez ensuite une collection pour entraîner votre modèle, et sélectionnez les documents spécifiques de cette collection que vous souhaitez utiliser comme données d'entraînement. Vous pouvez inclure dans l'entraînement la dernière version de toutes les pages (avec les régions de texte) ou limiter le jeu de données aux pages de référence (Ground Truth).
Pour sélectionner manuellement les pages à inclure dans le jeu d'entraînement, cliquez sur « Select Pages » (dans l'aperçu du document). Ce menu affiche une liste des pages avec un petit apercu. Vous pouvez sélectionner ou désélectionner les pages individuellement. Cliquez sur « Save and go back » pour poursuivre la configuration de l'entraînement.
Étape 2 : Sélectionner les balises
Sélectionnez les balises de structure que vous avez préparées lors de la compilation préalable des données d'entraînement. Ce sont les balises que le modèle apprendra à reconnaître.
Vous pouvez également inclure des régions non balisées dans l'entraînement. Si vous ne sélectionnez pas cette option, les régions non balisées seront négligées et le modèle résultant ne sera pas capable de les reconnaître.

Bon à savoir : les Field Models peuvent également être entraînés sur des polygones de ligne , c'est-à-dire des formes englobant tout le texte manuscrit d'une ligne (l'algorithme sous-jacent est le même). Tandis que les lignes de base se situent en dessous de la ligne de texte, les polygones de ligne couvrent entièrement les lettres, y compris les jambages. Les polygones de ligne sont calculés automatiquement à partir des lignes de base pendant la reconnaissance de texte (ou l'entraînement). Cependant, cela peut entraîner des résultats imprécis (par exemple, pour des caractères particulièrement grands, des notes de musique ou des expressions mathématiques), ce qui peut à son tour provoquer des erreurs dans la reconnaissance de texte.
Si c'est le cas et que vous devez entraîner un modèle de polygones de ligne, corrigez les polygones de ligne dans la Ground Truth et cochez la case « Train on line polygons » pour entraîner un Field Model capable de reconnaître ces polygones.
-png.png?width=688&height=141&name=Recognise%20(5)-png.png)
Étape 3 : Données de validation
Une fois les données d'entraînement prêtes, il est temps de sélectionner les données de validation. Il y a deux options : l'une est déjà sélectionnée automatiquement, l'autre doit être activée manuellement. La sélection automatique ne requiert que de sélectionner un pourcentage de pages du jeu de données à utiliser comme données de validation (nous recommandons 10 %).
Sinon, vous pouvez sélectionner manuellement des pages spécifiques pour vos données de validation.
Étape 4 : Configurer un modèle
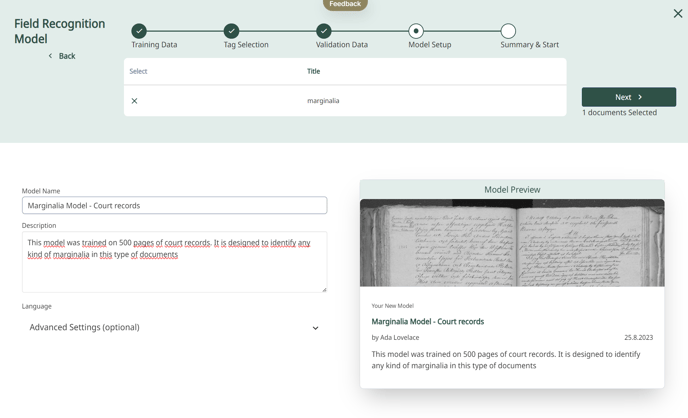
Lorsque le jeu d'entraînement est prêt, tout ce qu'il vous reste à faire est d'ajouter quelques informations sur votre modèle.
- Nom du modèle : Choisissez un nom pour votre nouveau modèle. Par exemple, vous pouvez décrire en quelques mots pour quelle mise en page votre modèle est conçu.
- Description : Décrivez brièvement le matériel que vous avez utilisé comme GT et pour quel type de document votre modèle est adapté (par exemple, des formats in-octavo avec des marginalia manuscrits ou des documents administratifs avec des tableaux).
- Aperçu : Vous pouvez également ajouter une image en tant qu'aperçu de votre modèle. Pour ce faire, copiez l'URL de l'image.
De plus, il est possible d'activer des options avancées pour le processus d'entraînement.
La première option avancée concerne le nombre de cycles d'entraînement. Ces cycles indiquent combien de fois (entre 1 000 et 30 000) le modèle parcourras les données d'entraînement pour apprendre et s'ajuster. Plus le nombre de cycles est élevé, plus le modèle sera précis, mais cela augmente également le risque de surapprentissage (overfitting).
Ensuite, vous pouvez définir un taux d'apprentissage. Il détermine l'incrément (entre 0,001 et 0,05) d'un cycle à l'autre, ce qui influence la vitesse à laquelle l'entraînement progresse. Cela a des conséquences sur la précision : plus la valeur (donc la vitesse) est élevée, plus le risque de négliger des détails est important.
Pour les premiers entraînements, il est conseillé de ne pas toucher à ces paramètres avancés et de rester sur les options par défaut, qui ont fait leurs preuves dans la plupart des cas.
Étape 5 : Aperçu
Votre modèle est prêt pour l'entraînement ? Vérifiez toutes les configurations et données que vous avez saisies. Une fois tout prêt, procédez en cliquant sur « Start » pour démarrer le processus d'entraînement.
Vous pouvez vérifier l'avancement de l'entraînement en cliquant sur le bouton « Jobs » dans la barre en haut à droit, à gauche de votre icône utilisateur. Vous recevrez un courriel dès que le processus d'entraînement sera terminé.
Comment utiliser le Field Model entraîné
Une fois que votre nouveau Field Model est prêt, vous pouvez le tester sur vos documents.
1. Sélectionner des documents pour la reconnaissance
Allez sur le Transkribus Desk et sélectionnez les documents ou les pages spécifiques que vous souhaitez faire reconnaître.
Veuillez noter que votre modèle fonctionnera mieux sur des documents similaires à ceux du jeu d'entraînement. Par exemple, s'il a été entraîné uniquement avec des livres au format in-folio comportant un corps de texte simple, des numéros de page et des titres, les résultats pourraient ne pas être à la hauteur des attentes pour des livres avec des en-têtes et des pieds de page.
-png.png?width=600&height=383&name=Field%20(1)-png.png)
2. Processus de reconnaissance
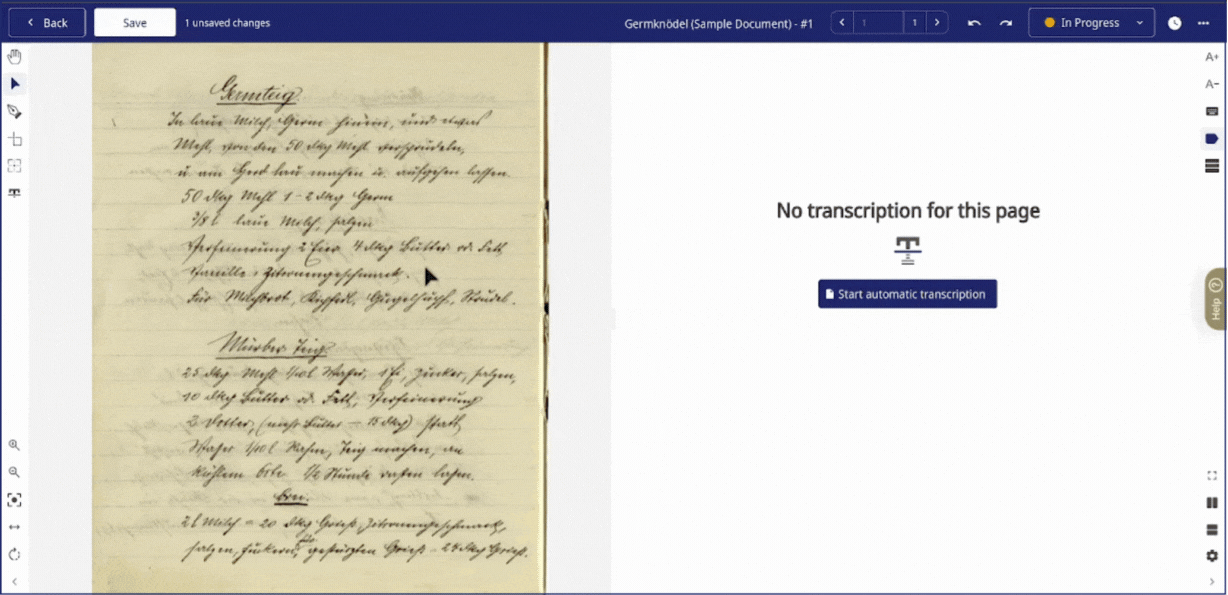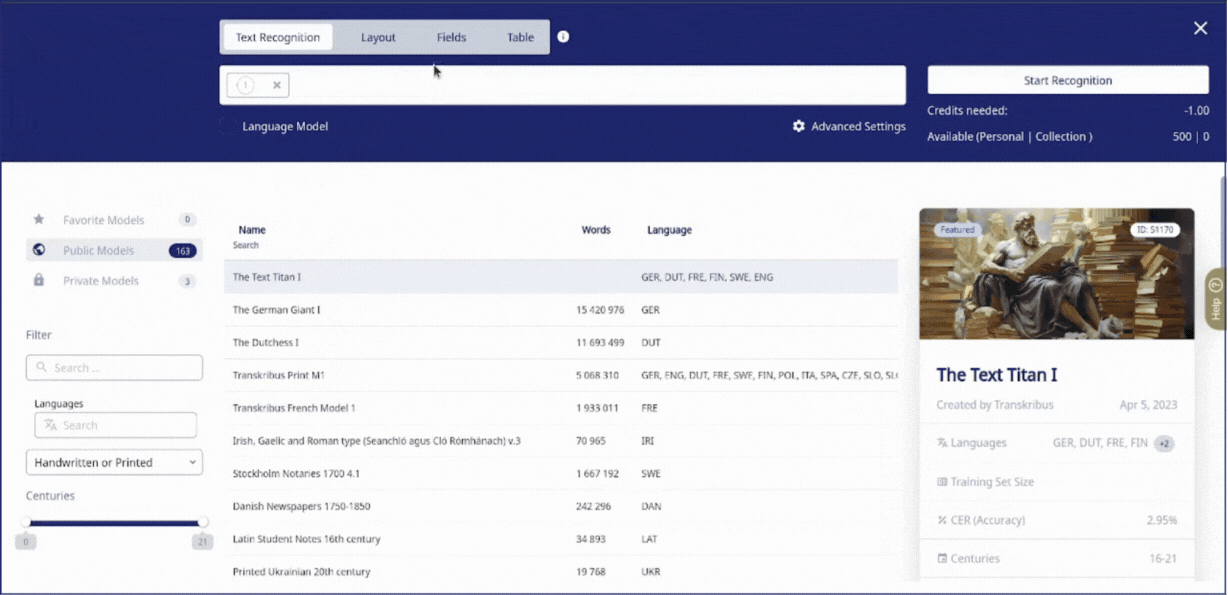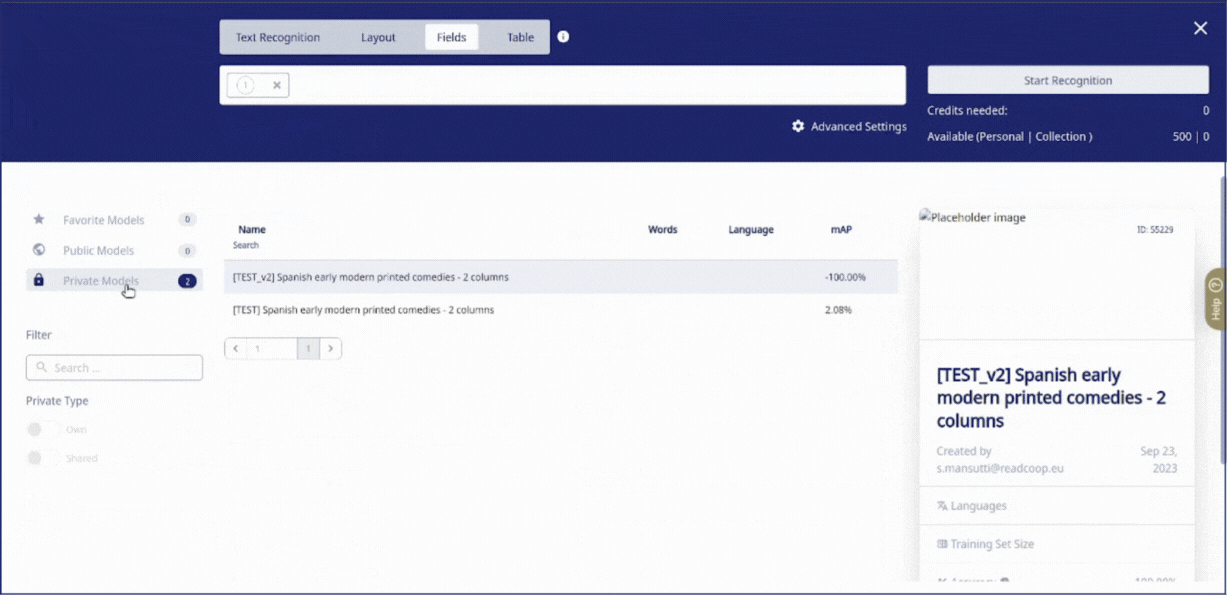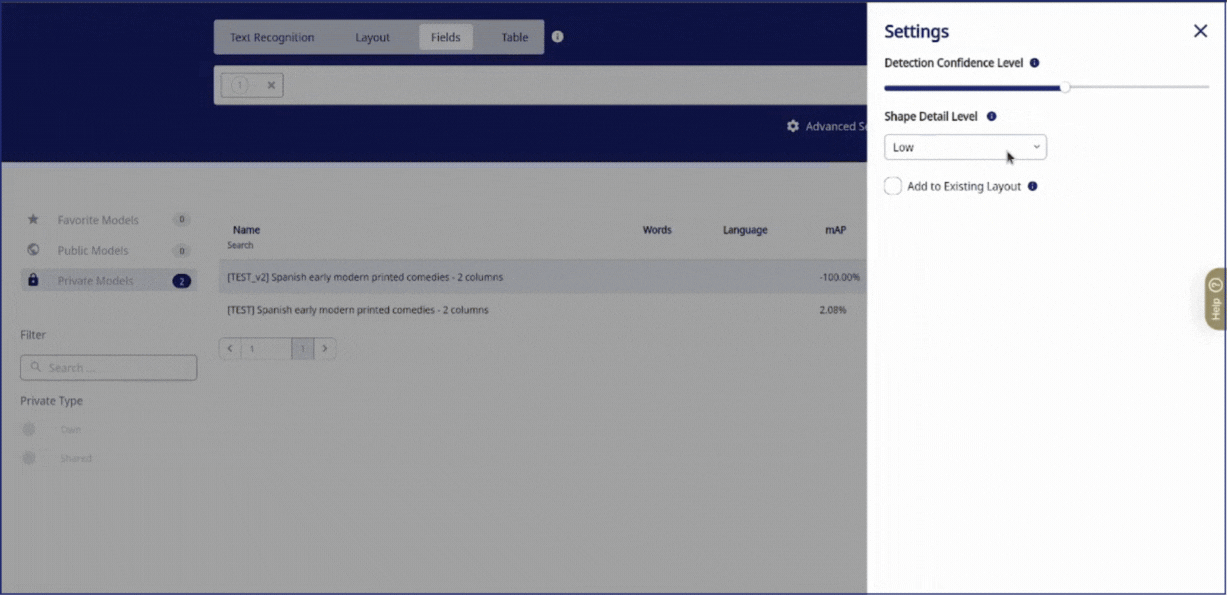
Ouvrez la page sur laquelle vous souhaitez tester votre modèle et cliquez sur « Recognition » dans la barre en bas à gauche de l'éditeur pour accéder au menu de reconnaissance. Ensuite, passez à Fields et sélectionnez votre nouveau Field Model dans la liste des modèles privés.
Par ailleurs, il est possible d'activer des options avancées pour la reconnaissance :
- Detection Confidence Level : ce paramètre (compris entre 0,5 et 1) détermine le niveau de certitude requis pour que le modèle marque un champ.
- Shape Detail Level : détermine le niveau de détail des formes des champs. 'High' conserve la complexité des champs; 'Low' simplifie les formes à des structures de base; 'Medium' offre un équilibre entre le détail et la simplicité.
- Add to Existing Layout : en activant cette case, le modèle applique des balises à la mise en page existante ou ajoute de nouveaux champs en fonction des paramètres du modèle.
Et voilà ! Votre Field Model peut désormais être utilisé pour reconnaître la mise en page des documents ou des pages sélectionnés.