Durch die trainierbaren Field Models ist es möglich, mit Transkribus eine Vielzahl von unterschiedlichen Layoutarten automatisch zu erkennen und zu transkribieren. Im Folgenden wird erklärt, wie Sie ein leistungsstarkes Field Model trainieren und anwenden können.
Trainieren eines Field Models
1. Vorbereitung der Trainingsdaten im Transkribus Desk
Vor dem Training eines Field Models müssen die sogenannten Trainingsdaten, also die Seiten und Daten, auf denen das Modell trainiert werden soll, vorbereitet werden. Für die Vorbereitung dieser Daten müssen die historischen Dokumente, die im Training verwendet werden sollen, in eine bestimmte Collection im Transkribus Desk importiert werden. Danach können sie im Transkribus-Editor geöffnet werden, um darin Textregionen zu definieren und Zeilen hinzuzufügen. Als Nächstes muss die Struktur, d. h. die Layoutelemente im Dokument, wie in diesem Artikel erklärt, mit Tags versehen werden. Die Änderungen müssen schließlich gespeichert werden.
Wurden genug Seiten mit Tags versehen (wir empfehlen mindestens 50 Seiten je nach Komplexität des Dokumentenlayouts), kann das Modelltraining beginnen.
2. Trainieren eines Modells in Transkribus
Das Trainings-Setup besteht aus fünf Schritten: Trainingsdaten, Tag-Auswahl, Validierungsdaten, Modell-Setup und Übersicht & Start. Durch Klicken auf "Next" oder "Back" können Sie jederzeit zwischen zwei Schritten hin- und herspringen.
Bitte beachten Sie, dass es sich bei den Trainings- und Validierungsdaten um zwei unterschiedliche Komponenten desselben Datensets handelt. Die Trainingsdaten sind eine Sammlung von Beispielen, die verwendet werden, um die Modellparameter anzupassen (das Modell wird auf diesen Seiten trainiert). Die Validierungsdaten hingegen dienen als unabhängige Testdaten, die eine unvoreingenommene Bewertung der Genauigkeit des Modells ermöglichen.
Schritt 1: Auswahl der Trainingsdaten
Öffnen Sie den Models-Workspace, klicken Sie auf "Train New Model" und wählen Sie "Field Model", um auf das Trainings-Menü zuzugreifen.

Klicken Sie dann auf die Collection, in der Sie Ihr Modell trainieren werden und wählen Sie die Dokumente aus der Collection, die Sie als Trainingsdaten verwenden wollen. Sie können die neuesten Versionen der Seiten (mit Textregionen) ins Training mit einschließen oder den Datensatz nur auf die Ground-Truth-Seiten beschränken.
Um die Seiten für das Trainingsset manuell auszuwählen, klicken Sie auf "Select Pages" (in der Dokumentenvorschau). In diesem Menü sehen Sie eine Liste der Seiten mit kleinen Vorschaubildern. Hier können Sie einzelne Seiten aus- oder abwählen. Klicken Sie auf "Save and go back", um mit den Trainingseinstellungen fortzufahren.
Schritt 2: Tag-Auswahl
Wählen Sie die Struktur-Tags, die Sie während der vorangegangenen Zusammenstellung der Trainingsdaten vorbereitet haben. Diese Tags wird das Modell lernen zu erkennen.
Sie können auch unmarkierte Regionen in Ihr Training einbeziehen. Sollten Sie diese Option nicht auswählen, werden unmarkierte Regionen ignoriert und das resultierende Modell wird sie nicht erkennen.

Gut zu wissen: Field Models können auch auf Zeilenpolygone trainiert werden (der zugrunde liegende Algorithmus ist derselbe). Dabei handelt es sich um Formen, die den gesamten handgeschriebenen Text einer Zeile umschließen. Während die Baselines unter den Zeilen verlaufen, umfassen die Zeilenpolygone die Buchstaben in ihrer Gesamtheit, einschließlich Ober- und Unterlängen. Die Zeilenpolygone werden während der Texterkennung (bzw. während des Trainings) automatisch anhand der Baselines berechnet. Dabei kann es jedoch zu ungenauen Ergebnisse kommen (z. B. bei besonders großen Zeichen, Musiknoten oder mathematischen Ausdrücken), was wiederum zu Fehlern bei der Texterkennung führen kann.
Falls dies zutrifft und Sie aus diesem Grund ein Zeilenpolygon-Modell trainieren müssen, korrigieren Sie die Zeilenpolygone in der Ground Truth und aktivieren Sie das Kästchen "Train on line polygons", um ein Field Model für Zeilenpolygone zu trainieren.

Schritt 3: Validierungsdaten
Nach der Vorbereitung der Trainingsdaten sind nun die Validierungsdaten an der Reihe. Es stehen zwei Optionen zur Verfügung: Die eine ist bereits automatisch ausgewählt, die andere muss manuell aktiviert werden. Bei der automatischen Auswahl des Validierungssets muss lediglich ein Prozentsatz von Seiten aus dem Datensatz festgelegt werden, die dann als Validierungsdaten verwendet werden (wir empfehlen 10 %).
Alternativ können Sie spezifische Seiten manuell als Validierungsdaten auswählen.
Schritt 4: Modell-Setup
Ist das Trainingsset fertig, müssen Sie nur noch ein paar Informationen über Ihr Modell bereitstellen.
- Modellname: Geben Sie Ihrem neuen Modell einen Namen. Beispielsweise können Sie in ein paar Worten beschreiben, für welches Layout das Modell gedacht ist.
- Beschreibung: Beschreiben Sie kurz, welches Material Sie für die Ground Truth verwendet haben und für was das Modell geeignet ist (z. B. Oktavformate mit handgeschriebenen Marginalien oder administrative Dokumente mit Tabellen).
- Vorschaubild: Optional können Sie ein Bild als Vorschau Ihres Modells hinzufügen. Kopieren Sie dazu die Bild-URL.
Es gibt außerdem die Möglichkeit, erweiterte Optionen für den Trainingsprozess auszuwählen.
Die erste erweiterte Option betrifft die Anzahl der Trainingszyklen. Diese gibt an, wie oft das Modell die Trainingsdaten durchläuft (zwischen 1.000 und 30.00), um daraus zu lernen und entsprechend Anpassungen vorzunehmen. Je höher die Anzahl der Durchgänge, desto genauer wird das Modell, aber auch das Risiko einer Überanpassung (Overfitting) steigt.
Als nächstes kann eine Lernrate festgelegt werden. Sie bestimmt die Schrittgröße (zwischen 0,001 und 0,05) von einem Zyklus zum nächsten und somit, wie schnell das Training voranschreitet. Das hat wiederum Auswirkungen auf die Genauigkeit: je höher der Wert (also die Geschwindigkeit), desto höher das Risiko, dass Details übersehen werden.
Für die ersten Trainings empfiehlt es sich, diese Parameter nicht zu ändern und die voreingestellten erweiterten Optionen beizubehalten, da diese sich für die meisten Szenarien als effektiv erwiesen haben.
Schritt 5: Übersicht
Ihr Modell ist bereit für das Training? Überprüfen Sie zunächst alle vorgenommenen Einstellungen und Eingaben. Sobald Sie zufrieden sind, klicken Sie auf "Start", um mit dem Trainingsprozess zu beginnen.
Sie können den Trainingsfortschritt überprüfen, indem Sie auf den Jobs-Button in der Leiste rechts oben, links neben Ihrem User-Icon klicken. Sie erhalten eine E-Mail sobald der Trainingsprozess beendet wurde.
Verwendung des trainierten Field Models
Ist ihr neues Field Model fertig, können Sie es auf Ihren Dokumenten ausprobieren.
1. Auswahl der Dokumente für die Erkennung
Öffnen Sie Ihren Transkribus-Desk und wählen Sie die Dokumente oder Seiten aus, die Sie erkennen lassen wollen.
Beachten Sie dabei, dass Ihr Modell auf Dokumenten, die dem Trainingsset ähneln, besser funktioniert. Wurde es beispielsweise nur mit Büchern im Folioformat mit einfachem Fließtext, Seitenzahlen und Überschriften trainiert, könnten die Ergebnisse bei Büchern mit Kopf- und Fußzeilen unter den Erwartungen bleiben.
2. Erkennungsprozess
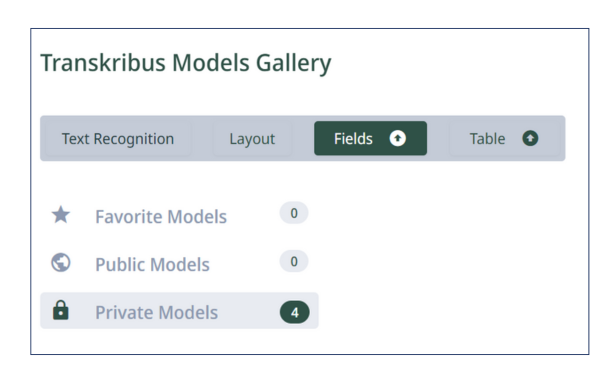
Öffnen Sie die Seite, auf der Sie das Modell testen wollen und klicken Sie auf "Recognition" in der oberen linken Leiste des Editors, um das Erkennungsmenü aufzurufen. Wechseln Sie dann zu Fields und wählen Sie unter Private Models ihr neu trainiertes Modell aus.
Optional gibt es die Möglichkeit, erweiterte Einstellungen für die Erkennung vorzunehmen:
- Detection Confidence Level: Dieser Parameter (zwischen 0,5 und 1) bestimmt, wie sicher das Modell sein muss, bevor es ein Feld markiert.
- Shape Detail Level: bestimmt den Detaillierungsgrad der Formen der Felder. "High" erhält die Komplexität der Felder; "Low" vereinfacht die Formen auf grundlegende Strukturen; "Medium" bietet eine ausgewogene Balance zwischen Detail und Einfachheit.
- Add to Existing Layout: Durch Aktivieren dieses Kästchens versieht das Modell das vorhandene Layout mit Tags oder fügt entsprechend den Modelleinstellungen neue Felder hinzu.
Und das war's auch schon! Ihr Field Model kann nun eingesetzt werden, um das Layout der ausgewählten Dokumente oder Seiten zu erkennen.