Passo precedente: Riconoscimento manuale del layout
Lo strumento predefinito di Riconoscimento layout (Preset Model) funziona bene per la maggior parte delle tipologie di documenti, ma potrebbe non essere altrettanto accurato con i documenti con layout complessi, come registri, documenti annotati, cartoline, ecc.
Quando il riconoscimento del layout predefinito non è soddisfacente per i vostri documenti, potete addestrare un modello Baselines specifico per la vostra tipologia di documento. Dopo la formazione, è possibile applicare il modello Baselines personalizzato ai documenti, che saranno segmentati in base agli esempi forniti per l'allenamento.
Prima di iniziare l'addestramento di un modello Baselines, ricordate la differenza tra esso e P2PaLA. P2PaLA riconosce automaticamente la struttura dei vostri documenti, arricchendoli con tag strutturali. Al contrario, un modello Baselines rileva solo le linee, ma ha il vantaggio di essere specificamente addestrato sul layout dei documenti. Per questo motivo, dovrebbe essere più preciso del Preset Model predefinito.
Il primo passo è preparare le pagine su cui addestrare il modello Baselines. Un buon numero per iniziare è 50 pagine, ma l'efficienza del modello dipende dalla complessità del layout. Dopo il primo addestramento con 50 pagine, si può decidere se il modello Baseline è abbastanza buono o se ha bisogno di altro materiale di addestramento.
Per preparare le pagine, è sufficiente segmentare, automaticamente o manualmente, le regioni di testo e le linee di base. A seconda della complessità del layout, ci sono tre opzioni per segmentare le pagine:
- Eseguire l'impostazione predefinita riconoscimento automatico del layout.
- Aprire la pagina e disegnare manualmente le regioni di testo utilizzando il pulsante "Aggiungi regione" a sinistra dell'immagine. Eseguire quindi il Riconoscimento automatico del layout per rilevare le linee; prima di eseguirlo, ricordarsi di deselezionare l'opzione "Rileva regioni". Infine, passare in rassegna le pagine e correggere le righe manualmente.
- Aprire la pagina e disegnare manualmente le regioni di testo e le linee di base.
La scelta dell'opzione dipende dal tipo di documento e dalle scarse prestazioni del riconoscimento automatico del layout di default.
Non è necessario aggiungere alcuna trascrizione alle pagine prima dell'addestramento del modello Baselines, poiché questo si concentra solo sulle linee di base e la presenza di testo trascritto è irrilevante.
Una volta che le 50 o più pagine sono state segmentate, è il momento di addestrare il modello Baselines.
Fare clic sulla scheda "Formazione" nella barra superiore, a destra di "Workdesk". Quest'area è dedicata all'addestramento di entrambi i modelli Text Recognition e Baselines: in questo caso, scegliere Baselines Model.
Poi, è necessario selezionare la raccolta contenente le pagine con il layout corretto. Digitare il titolo della collezione o l'ID della collezione e selezionarlo.
Dopo aver scelto la collezione, inizia l'impostazione dell'addestramento vero e proprio.
-
Impostazione del modello
Le prime informazioni che vi viene chiesto di inserire sono il nome del modello (scelto da voi) e una descrizione del vostro modello e dei documenti su cui è stato formato (materiale, periodo, tipo di layout...).
Sotto si vede il numero di epoche. Il numero di epoch si riferisce al numero di volte in cui l'algoritmo di apprendimento lavorerà attraverso l'intero dato di addestramento e valuterà se stesso sia sul dato di addestramento che su quello di validazione. 100 epoche funzionano bene per la maggior parte degli addestramenti di modelli di base.
Si può quindi decidere quale versione della pagina utilizzare per la formazione: l'ultima trascrizione o solo Ground Truth. Con la prima opzione, tutte le ultime modifiche, indipendentemente dal modo in cui sono state salvate, vengono visualizzate e possono essere selezionate per la formazione. Se si sceglie "Only Ground Truth", sono selezionabili solo le pagine salvate come Ground Truth.
-
Training Data
Durante l'addestramento, le pagine Ground Truth vengono divise in due gruppi:
- Training Data: insieme di esempi utilizzati per adattare i parametri del modello, cioè i dati su cui si basa la conoscenza della rete. Il modello viene addestrato su queste pagine.
- Validation Data: insieme di esempi che forniscono una valutazione imparziale di un modello, utilizzati per mettere a punto i parametri del modello durante l'addestramento. In altre parole, le pagine dei dati di convalida sono messe da parte durante l'addestramento e vengono utilizzate per valutarne l'accuratezza.
In questa pagina, scegliere le pagine da includere nel Training Data. Selezionando la casella vicino al titolo del documento, è possibile selezionare tutte le trascrizioni disponibili nel documento. Ma è anche possibile fare clic sul pulsante più, espandere il contenuto del documento e selezionare solo alcune pagine. Le pagine selezionate verranno elencate sulla destra.
Le pagine che non contengono righe non possono essere selezionate. Per visualizzare il documento o una pagina in una nuova scheda, fare clic sull'icona dell'occhio.
-
Validation Data
Scegliere le pagine da assegnare ai dati di convalida.
È possibile selezionare le pagine manualmente o assegnarle automaticamente.La selezione manuale funziona come descritto sopra per il Training Data. Sono selezionabili solo le pagine che contengono testo e che non sono state incluse nei Dati di addestramento.
Con la selezione automatica, il 2%, il 5% o il 10% del Training Data viene assegnato automaticamente al Validation Data: in questo caso, è sufficiente fare clic sulla percentuale che si desidera assegnare. La selezione automatica è consigliata per avere una maggiore varietà di dati di convalida.
Dopo aver controllato tutti i dettagli, fare clic su "Start Training" per avviare l'addestramento. È possibile seguire l'andamento della formazione facendo clic sul pulsante "Lavori" nel menu a sinistra di "Transkribus Organizer". Il completamento di ogni epoca sarà indicato nella descrizione del lavoro e si riceverà un'email quando il processo di formazione è completato.
A seconda della quantità del materiale, l'addestramento potrebbe richiedere un po' di tempo. Nella finestra "Jobs", potete controllare la vostra posizione nella coda (cioè il numero di formazioni che vi precedono). È possibile eseguire altri lavori in Transkribus o chiudere la piattaforma durante il processo di formazione. Se lo stato del lavoro è "created" o "running", non iniziare una nuova formazione, ma avere pazienza e aspettare.
Una volta terminata la formazione, è possibile utilizzare il modello Baselines per riconoscere il layout dei documenti. Selezionare la pagina o le pagine o il documento da elaborare, quindi fare clic su "Riconoscimento layout" nel menu a sinistra sotto "Strumenti". Invece di usare il Modello preimpostato, scegliere il modello Baselines che si è addestrato.
Tra i dettagli del modello, è presente una percentuale: si tratta della Perdita (Loss) del Validation Data. Misura la percentuale di pixel classificati in modo errato e indica come si comporta il modello Baselines su nuove pagine su cui non è stato addestrato. Risultati con una perdita del 10% o inferiore significano che il modello Baselines è efficace.
Una volta terminato il lavoro, aprire la pagina/le pagine e le regioni di testo e le linee di base appariranno nelle immagini. Nessun credito sarà utilizzato per applicare il modello Baselines ai vostri documenti.
Passo successivo: P2PaLA
Transkribus eXpert (deprecato)
Lo strumento predefinito Riconoscimento layout (Modello preimpostato) funziona bene per la maggior parte delle tipologie di documenti, ma potrebbe non essere altrettanto accurato con documenti dal layout complesso, come giornali, cartoline, registri, documenti annotati, ecc.
Quando l'analisi del layout predefinita non è soddisfacente per i documenti, è possibile addestrare un modello Baselines specifico per la tipologia di documento. Dopo la formazione, potrete applicare il vostro modello Baselines personalizzato ai vostri documenti, che verranno segmentati seguendo gli esempi forniti per la formazione.
Prima di iniziare l'addestramento di un modello Baseline, ricordate la differenza tra esso e P2PaLA. P2PaLA riconosce automaticamente la struttura dei vostri documenti, arricchendoli con tag strutturali. Al contrario, un modello Baselines rileva solo le linee di base, ma ha il vantaggio di essere specificamente addestrato sul layout dei documenti. Per questo motivo, dovrebbe essere più preciso dello strumento predefinito di riconoscimento dell'analisi del layout.
Il primo passo è preparare le pagine su cui addestrare il modello Baselines. Un buon numero per iniziare è 50 pagine, ma l'efficienza del modello dipende dalla complessità del layout. Dopo il primo addestramento con 50 pagine, si può decidere se il modello Baselines è abbastanza buono o se ha bisogno di altro materiale di addestramento.
Per preparare le pagine, è sufficiente segmentare, automaticamente o manualmente, le regioni di testo e le linee di base. A seconda della complessità del layout, ci sono tre opzioni per segmentare le pagine:
- Eseguite l'analisi automatica predefinita del layout che si trova nella scheda "Strumenti" e poi correggetela manualmente usando il menu Canvas.
- Disegnare manualmente le regioni di testo utilizzando il pulsante "+TR" nel menu Tela. Quindi, nella scheda "Strumenti", eseguite l'analisi automatica del layout per rilevare le linee di base: prima di eseguirla, ricordate di deselezionare l'opzione "Trova regioni di testo". Infine, passare in rassegna le pagine e correggerle manualmente utilizzando il Menu Canvas.
- Disegnate manualmente sia le regioni di testo che le linee di base, utilizzando rispettivamente il pulsante "+TR" e il pulsante "+BL" del menu Tela.
L'opzione da scegliere dipende dal tipo di documento e dalle scarse prestazioni del riconoscimento automatico dell'analisi del layout.
Non è necessario aggiungere alcuna trascrizione alle pagine prima dell'addestramento del modello Baselines, poiché questo si concentra solo sulle linee di base e la presenza di testo trascritto è irrilevante.
Una volta segmentate le 50 o più pagine, è il momento di addestrare il modello Baselines. Fare clic sulla scheda "Strumenti". Nella sezione "Formazione del modello", fare clic su "Formazione di un nuovo modello". Si apre la finestra di addestramento del modello e, sulla destra, si può scegliere il motore da addestrare: per il modello Baseline, selezionare "Baselines".
Prima di iniziare l'addestramento, inserire il nome e la descrizione del modello. È inoltre possibile modificare i parametri di addestramento, ossia il numero di epoche e il tasso di apprendimento. Per il primo addestramento e se non si ha familiarità con l'apprendimento automatico, non modificare questi parametri.
È quindi necessario selezionare le pagine che si desidera utilizzare per addestrare il modello, ossia le pagine precedentemente segmentate in regioni di testo e linee di base. A sinistra, selezionare l'intera collezione o le pagine interessate. Fare clic sul pulsante Training al centro per aggiungere le pagine selezionate al Training Set. Se si desidera considerare solo le pagine con lo stato di Ground Truth, selezionare "Solo Ground Truth" nel menu a discesa a destra, sotto "Panoramica".
Fare lo stesso per il set di convalida. L'insieme di convalida dovrebbe essere circa il 10% dell'insieme di addestramento, quindi suggeriamo, per il primo addestramento, di includere 45 pagine nell'insieme di addestramento e 5 pagine nell'insieme di convalida. Se si desidera assegnare automaticamente una percentuale del set di allenamento al set di convalida, selezionare una percentuale nell'opzione "selezione automatica del set di convalida" prima di fare clic sul pulsante "Allenamento".
Dopo aver completato questa fase, è possibile iniziare l'addestramento del modello Baselines facendo clic sul pulsante "Train". A seconda della quantità di materiale didattico, la formazione potrebbe richiedere un po' di tempo. Fare clic sul pulsante "Lavori" per controllare lo stato dei lavori o la propria posizione nella coda (cioè il numero di formazioni che precedono la propria). È possibile eseguire altri lavori in Transkribus o chiudere la piattaforma durante il processo di formazione. Se lo stato del lavoro è "creato" o "in corso", non iniziare una nuova formazione, ma avere pazienza e aspettare.
Una volta terminato l'addestramento, il modello di riferimento apparirà nella scheda "Server", sotto "Model Data". Per vederlo, selezionare "layout" invece di "testo" come tipo di output del modello nel secondo menu a discesa.
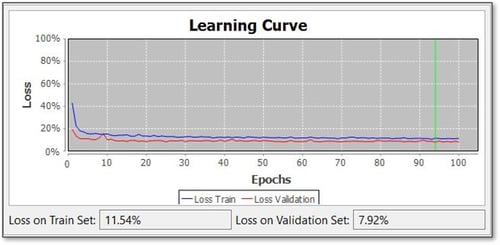
Facendo doppio clic sul nome del modello Baseline, si vedranno tutti i dettagli e la sua curva di apprendimento. Il grafico "Curva di apprendimento" mostra l'accuratezza del modello di base. L'asse delle ascisse indica il numero di epoche, ossia il numero di volte in cui vengono valutati i dati di addestramento. L'asse y misura la perdita, cioè la percentuale di pixel classificati in modo errato. Il programma si addestra prima sull'insieme di addestramento e poi si testa sulle pagine dell'insieme di validazione. Per questo motivo, nel grafico sono presenti due linee. La linea blu indica il progresso dell'addestramento; la linea rossa indica il progresso della valutazione sul set di validazione. È importante che le due curve non differiscano troppo. Se le due curve divergono, è molto probabile che il Training Set differisca troppo dal Validation Set e che il modello risultante non sia efficace.
Sotto il grafico, le due percentuali indicano come si comporta il modello di base sul Training Set e sul Validation Set in termini di perdita. La perdita sul set di validazione è il valore più significativo perché indica come il modello di base si comporta su nuove pagine su cui non è stato addestrato. I risultati con una perdita del 10% o inferiore significano che il modello Baseline è efficace.
Per applicare il modello Baseline addestrato ai documenti, accedere alla scheda "Strumenti". Nella sezione superiore "Analisi del layout", fare clic su "Configura". Viene visualizzata la finestra "Configurazione dell'analisi del layout": qui è possibile scegliere il modello Baselines che è stato addestrato.
In combinazione con il modello Baselines, è anche possibile modificare le impostazioni dell'analisi del layout (lunghezza minima della linea di base; soglia di accuratezza della linea di base; uso di separatori addestrati; max-dist per l'unione delle linee di base; numero di regioni di testo). Per ulteriori informazioni su queste impostazioni, consultare la pagina Riconoscimento automatico del layout.
Finalmente, fare clic sul pulsante "OK" in fondo alla finestra "Configurazione dell'analisi del layout". Il modello addestrato è stato selezionato.
Nella scheda "Strumenti", scegliere le pagine da segmentare e fare clic sul pulsante "Esegui": il lavoro di analisi del layout verrà avviato. È possibile verificarne l'avanzamento facendo clic sul pulsante "Lavori" nella scheda "Server". Una volta terminato il lavoro, ricaricare la pagina o le pagine e le regioni di testo e le linee di base appariranno nelle immagini. Nessun credito sarà utilizzato per applicare il modello Baseline ai vostri documenti.